Inserting Large Variable Column Data Files with SQL Server Integration Services – Part 2
Far too long ago, I posted part 1 of an article solving the import of large data files with varying columns using SQL Server integration Services (SSIS). This is the belated follow up. In part 1, I explained some example file structures and how we approach the problem of inserting these files, which all have a varying number of columns with different data types. The solution combines a mixture of SSIS script tasks, external C# code in a referenced DLL and a flexible SQL Server DB schema. This post will walkthrough my overall SSIS Control Flow, as well as detail how we translate a code based, dynamic object model into something well-defined which we can insert into a SQL Server DB.
To start with, you need 2 tables in your SQL DB to contain the transposed data, as well as a couple of temporary tables to house the same data during the insert.
An Attribute table:

The Attributes table provides a flexible list of columns and types detected from the source files.
And a Data table:

The Data table provides a staging area into which incoming data can be loaded.
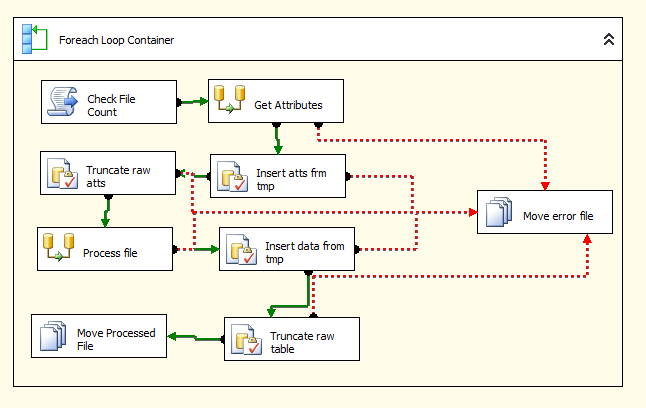
On both tables, the ID column should be an IDENTITY. This is set as bigint on the Data table as depending on the size of the files you’re inserting, int can overflow fast. Your temporary tables should follow the same structure, just without the ID column (tmp_Attribute and tmp_Data). Now that we have our tables set up, we can move on to the SSIS package. Roughly speaking, what we want to do is to open our source file using our C# DLL and build it up into an in-memory object, then bring that object through to SSIS and use that to insert into the DB. This can be visualised by looking at my SSIS Control Flow below:

SSIS Control Flow showing the steps to load variable format files into our Entity, Attribute, Value model.
Before we begin working through the Control Flow logic, there is one last thing required. You must add a new Package Variable of type Object. Let’s call this File. This is what we’ll use to store our in-memory object from C# and pass to SSIS for insertion.
The ForEach Loop is configured to iterate through all files within the specified source directory and store the current file name in a variable. Ignoring the first step (Check File Count) which is an unrelated file management task, you can see that the first thing we come to is to retrieve the required Attributes. Now, each row that we’re about to our Attribute table corresponds to a column within the source file. By using this Attribute table it means that we don’t care about position within the source file but we can re-use columns (i.e. Attributes) that have the same name.
The “Get Attributes” Data Flow Task consists of only 2 components, a Script Transformation (being used as a data source) and an OLE DB Destination, which should be configured to point to the temporary tmp_Attribute table.
Set up the Script Transformation with the current file name as a ReadOnlyVariable and our object, File as a ReadWriteVariable. you’ll also need to predefine the Outputs by clicking “Inputs and Outputs” and adding a new Output, with columns for both AttributeName and AttributeType, matching the columns in our table above.
Inside the Script Transformation code, we want to call our external DLL (added as a reference via the Global Assembly Cache), which will construct an object comprising of columns and rows. You could use a DataSet for this, or a custom object as I have done.
using System;
using System.Data;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
using YourExternalDllObjectModelReferenceHere;
Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute]
public class ScriptMain : UserComponent
{
private File _file;
public override void PreExecute()
{
base.PreExecute();
ImportCode ic = new ImportCode();
_file = ic.GetDocument(Variables.ActiveFilePath);
}
public override void PostExecute()
{
base.PostExecute();
//Add the doc to the var
Variables.File = _file;
}
public override void CreateNewOutputRows()
{
//Use external DLL to open file and work out attributes
foreach (ColumnEntity ce in _file.Columns.Entities)
{
Output0Buffer.AddRow();
Output0Buffer.AttributeName = ce.AttributeName;
Output0Buffer.AttributeType = ce.AttributeType;
}
Output0Buffer.SetEndOfRowset();
}
}
As you can see from the code listing, this will let the DLL do all the work building an object and simply pass this back to SSIS. In the CreateNewOutputRows() method, we physically define each output row, using each of the columns we’ve discovered using our DLL.
So we now have our entire data file in memory as our File object and our list of attributes sitting in the tmp_Attribute table. Next step in the Control Flow is to call a stored procedure to MERGE the data into the Attribute table. once finished, we should TRUNCATE the tmp_Attribute table ready for the next iteration of the ForEach loop.
Next it’s time to insert the data into the tmp_Data table which, I’m happy to say, is almost identical to the process above, with only one or two extra parts. Again, we need a Script Transformation Task as our Source and an OLE DB Destination pointing to tmp_Data as our Destination. This time however, we need to add a Lookup Transformation in between the two. Again, set up the Script Transformation with a custom Output, matching the rows in our tmp_Data table. Pass in the current file name and our File object as ReadOnlyVariables. The code for the Script Transformation is below:
using System;
using System.Data;
using System.Data.SqlClient;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
using YourExternalDllObjectModelReferenceHere;
Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute]
public class ScriptMain : UserComponent
{
private File _file;
public override void PreExecute()
{
base.PreExecute();
_file = (Document)Variables.Document;
}
public override void PostExecute()
{
base.PostExecute();
}
public override void CreateNewOutputRows()
{
if (_file != null)
{
int i = 0;
foreach (Row r in _file.Rows)
{
i++;
foreach (RowEntity re in r.Entities)
{
Output0Buffer.AddRow();
Output0Buffer.RowID = i;
Output0Buffer.AttributeName = re.AttributeName;
Output0Buffer.Date = DateTime.Now;
Output0Buffer.Value = re.Value.Substring(0, Math.Min(re.Value.Length, 1000));
}
}
Output0Buffer.SetEndOfRowset();
}
}
}
The Lookup then needs to perform a lookup on the Attribute table, retrieving the ID field where the AttributeName is equal to the AttributeName from our Script Transformation’s output. This is where we relate each row’s cell value back to the dynamic column from whence it came! As with attribute data previously, run this into tmp_Data and then use a Stored Procedure to MERGE into Data. Then TRUNCATE tmp_Data and we’re good to go.
After doing all of this, you should now be left with a nice, flexible solution that allows you to import large data files with completely different columns by transposing cells into rows in a SQL Server DB. The hard part is writing the cross-tab query with related mapping table to join these all these rows back up by RowID into an individual record, but that’s most definitely a story for another time.
I’d be delighted to hear any comments about the above solution or any recommendations for how to improve it in terms of performance or flexibility. I’ve been using this mechanism for over a year now and it’s very rarely let me down.