Inserting Large Variable Column Data Files with SQL Server Integration Services – Part 1
Just over a year ago I posted a question on my favourite programming Q&A site, Stack Overflow regarding an issue I was having with processing some large, variable column data files using SSIS (SQL Server Integration Services). Thanks to the great community there, I received an answer rather quickly and was able to develop a solution to solve the problem. I’ve been intending to document this for some time, as it’s a good solution, combining SSIS Control and Data Flow logic with custom C# code and a flexible SQL server database schema. I was working with a database schema which was set up to handle variable columns from a number of different files by transposing the columns into rows within the database. The upside of this is that it could support any number of columns from different files, in any order and with any type of data. The downside is that each row in a file, suddenly becomes row x column number of rows in the database, meaning processing large files can slow down exponentially if not handled correctly.
The image below gives an example of the file structures with which I was dealing and the table structure into which I was inserting the transposed data:
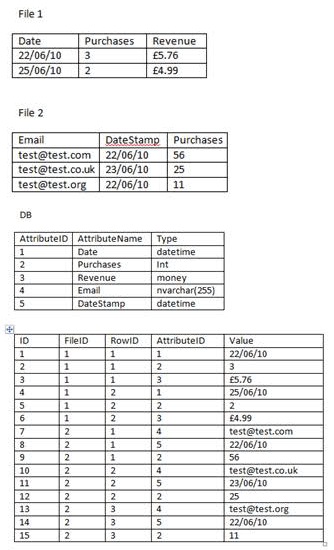
Example of the variable column file structure and the database tables used to store transposed data
SSIS is great for processing data files but because you define your File Connection Manager components at design time, they’re not geared up to support anything that may change from one file to another. For that, you’re supposed to use a different File Connection Manager. That’s fine if you have maybe three or four variations in the files that you’re importing, however for my situation, I had literally hundreds of different combinations of file formats, column names and data types. In this situation, you’re options become rather more limited and the best way to handle these subtle difference is to use your own code to load the file and build up the model via the incredibly versatile SSIS Script Task.
Originally, I was using a dynamically created string to insert the data (I know, I know) which rather unsurprisingly, displayed an enormous ratio of degradation as file sizes increased. Using this method of constructing the dynamic SQL and executing it against the database, we saw decent performance on small files (< 1MB) but this quickly slowed to a crawl as file size grew. Once we hit the 20MB+ mark, we were inserting at a rate of around 1MB per minute. With a couple of hundred files to insert each day and around half of them around the 20MB mark or bigger (up to 300MB), it didn’t take long to figure out that this solution was unworkable. So, I headed over to StackOverflow and posted my question.
The solution suggested to me by a fellow StackOverflow user was to let SSIS handle the data insertion and rather than constructing a string in my C# code, build up a data model in and SSI script task instead. I already had some C# code in place which processed the file in question and built up a custom object model before constructing the dynamic SQL, so I figured that it wouldn’t be too much of a stretch to change the access modifiers for some of the methods and expose the object model to SSIS.
Now that I’ve outlined the problem and how to approach the solution, in Part 2 of this post, I’ll describe exactly how the C# code in my SSIS Script Task built up the object model within SSIS and inserted into the database.
In the meantime, if you wish to view the innocuous question that spawned this post, you can find it over on StackOverflow under the catchy moniker, “Performance issues with transpose and insert large, variable column data files into SQL Server”.