Optimising SSIS to read from a view using OLE DB Source
I’ve really been neglecting the blog of late and have been taking a bit of a break from a lot of extra curricular business intelligence and data reading. I figured it was about time to get back to posting though, and as luck would have it, my colleague Stephen came to me with an interesting SSIS performance issue that presented the perfect opportunity for a quick blog post. I’ve not written much about SSIS lately, having been drawn off by the shiny sparkle of developments in the self-service BI sector such as Power BI, and playing with Big Data tools like Hadoop. But I still do a lot of work with SSIS and it’s still my go-to large scale ETL tool.
The OLE DB View Problem
Stephen’s problem was that he had an SSIS package that was loading some data from SQL server by reading a couple of views (producing symmetrical data), which was taking around 100 times longer to read the data than by querying the views directly via SQL.
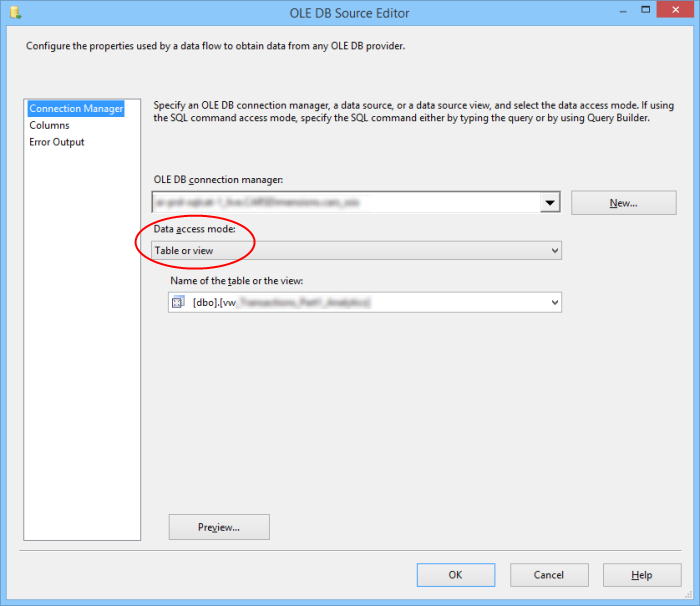
An SSIS OLE DB source using Table or View access mode
Figure 1 shows part of Stephen’s SSIS package, which is configured to load the data in parallel from two separate views which reside on the same server, then move them into an empty table on their separate destination servers. When he tested the views by querying them in SSMS, everything went fine and they brought data back in a matter of seconds. Looking at the query plan, the estimated number of rows was spot on, and the index usage was fine too. However, the execution plan did show a Nested Loop, and when he ran the SSIS package on the server, it took over 10 minutes to complete that individual Data Flow Task.
There’s a great blog post from the SQL Server Performance team that explains the cause behind this behaviour. Basically, using an OLE DB source in Table or View access mode causes SSIS to issue an OPENROWSET command, which results in SQL caching an inefficient execution plan (using Nested Loops), which causes slow query performance.
Improving SSIS performance
Fortunately, it’s a very simple fix. In your OLE DB source in your SSIS package, change the Data access mode property to SQL command. This will cause SSIS to validate the data source and examine the view’s columns at this stage, which leads to a more efficient execution plan (i.e. Hash Match) which will be used at runtime, resulting in a huge performance improvement.
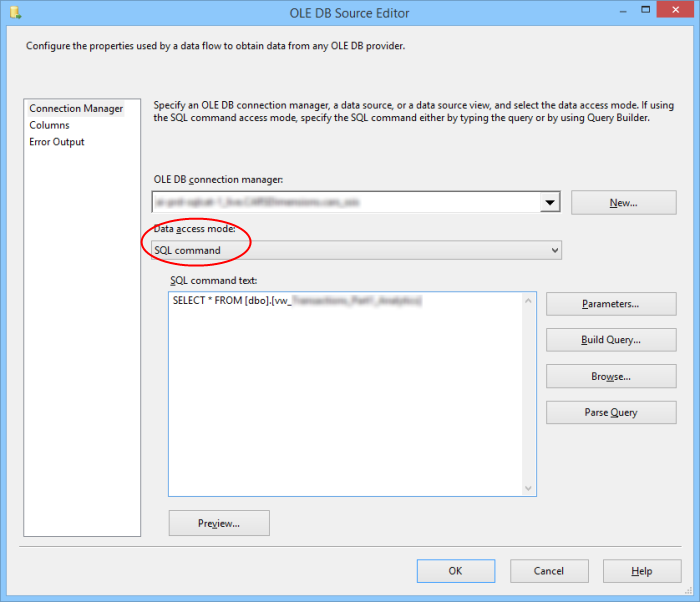
An SSIS OLE DB source using SQL command access mode
A very simple technique to speed up the performance of SSIS in a very common scenario. The fact that the SQL Performance Team blogged about it six years ago just shows that even though the technology changes, sometimes the old quirks remain.