Is AWS retiring the ds2.xlarge Redshift node type?
It’s rampant speculation time. AWS have released a number of nice features for Redshift over the last few months, from maintenance improvements like auto-vacuum and auto-analyze, to time savers like the in-browser query editor and new cluster configuration recommendation tool, that helps you find the right cluster configuration for your needs. It’s these two features that lead me to my wild assumption in the title, for one main reason - neither of them support the ds2.xlarge node type.
Now, by itself, this isn’t really evidence of anything, but I find it rather strange that both these new features have support for dc2.large and dc2.8xlarge, as well as ds2.8xlarge node types. That’s three of the four (current generation) node types available on Redshift. So why wouldn’t they support ds2.xlarge as well?
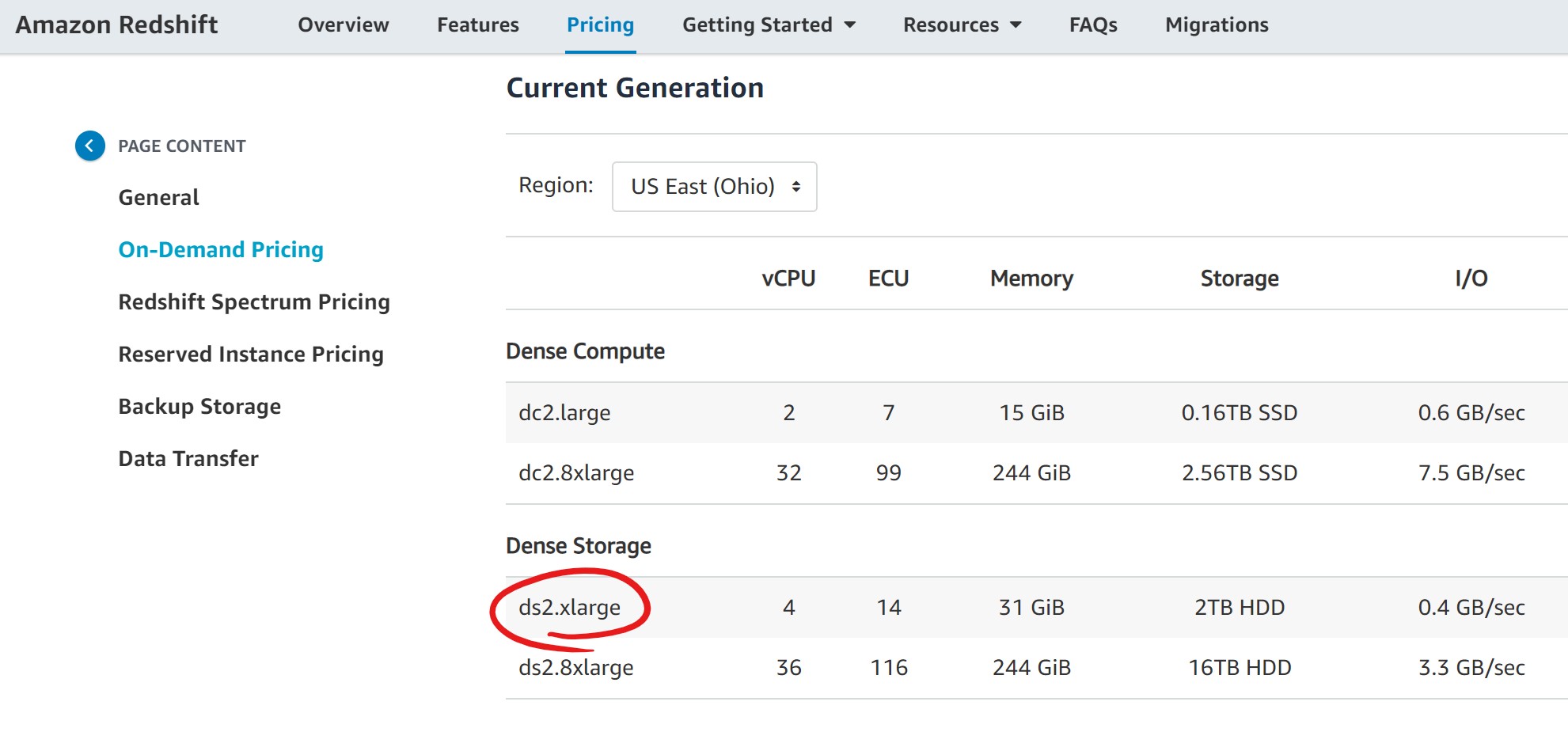
What is the ds2.xlarge node type?
The ds2.xlarge node type is a dense-storage node type, backed by magnetic disc. This means it has the lowest I/O throughput of all the current generation node types, but comes with a respectable 2TB disc per node, meaning it’s a good choice for decent sized data that perhaps doesn’t need blazing fast analysis. Redshift offers a lot of scope for optimising the data structure and table configuration on disc via distribution keys, compression etc., so it’s a perfectly usable (and cheap) node type for batch operations and less “hot” analysis. Especially now that Redshift Spectrum is available to provide elastic compute capacity.
In terms of storage then, ds2.xlarge (2TB) has slightly less than the SSD-backed dc2.8xlarge (2.5TB), but is around 1/6th of the price per node. The large increase is due to the fact that the big dc2 is a dense-compute node, built for speed and throughput. But as the data volumes grow, these nodes can get expensive, fast.
Compare the ds2.xlarge to the “mini” dc2.large node (the cheapest available), and while it offers slightly worse I/O (again due to the dc2s being SSD-backed), the ds2 absolutely smokes the dc2 for storage, as the compute-optimised node offers only 0.16TB per node. The strength of the dc2.large lies in its low cost and modest performance - a great node type for development and proof of concept work.
2 + 2 = 5
With the above in mind, it kind of seems like AWS are moving their proposition around to focus on providing the dc2.large as the “entry-level” node type to use in order to get you up and running. When it comes to production workloads, it’s then a straight-up shootout between the compute-optimised dc2.8xlarge for speed, and the storage-optimised ds2.8xlarge for straight up capacity (a whopping 16TB per node) to handle the largest workloads.
As I say, I might be totally off-base with this (it wouldn’t be the first time), but it just seems a little strange to exclude just the one node type from some of the new feature releases. I’m sure if they do retire the ds2.xlarge node type, there’ll be an extended support period and a migration path for anyone on reserved instances (they offered free upgrades from dc1 when they launched the dc2 family).
I’m interested to hear anyone else’s thoughts on this. Have you spotted any other Redshift features that exclude ds2.xlarge? Think I’m way off with this one? Let me know below.