Is Hadoop the right tool for the job?
I recently posted some thoughts regarding Microsoft’s Windows-compatible Hadoop implementation, HDInsight. I was investigating it for a project that I figured would benefit from a distributed processing approach, although ultimately decided to pursue other alternatives. It led our team to make some quite interesting discoveries about Hadoop, and some scenarios of when current distributed processing solutions are and aren’t appropriate.
Example scenario
The project in question is actually a large-scale data processing solution, required to process millions of varied data files daily, parsing data points from JSON, XML, HTML and more, and writing to a storage solution. Going back to the “Big Data” terminology, we were definitely looking at the potential for moving Terabytes of data per day, at least once we scale up, so needed a technology that could handle this, while remaining responsive, as processing time is actually a crucial factor.
What we quickly noticed, was that we actually didn’t need to use the Reduce part of the functionality. All we wanted to do was just simply run Map jobs to identify and retrieve data points, rather than aggregating and summarising said data points.
Distributed processing options
Following investigation of, and subsequent rejection of HDInsight as a viable option for this project, we took a look into vanilla Hadoop, as well as some other distributed processing implementations and Hadoop add-ons. Fortunately, there are a lot of very cool products out there.
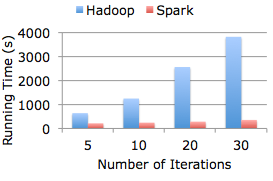
Spark claims to run up to 100x faster than Hadoop MapReduce
Cloudera Impalaactually introduces its own distributed query engine, which avoids MapReduce to deliver near real-time query results. It’s not intended as a replacement for MapReduce however, and is meant to complement a Hadoop cluster by offering alternative query techniques for accessing data from Hive and HDFS.
To properlyevaluate the performance of these products against one another,we realised we needed a baseline. Having a great deal of MS BI experience in our team, we thought it would be fun to create this baseline using our usual go-to data processing solution: SSIS.
The more we dug into the distributed architecture, the more it seems like we were looking for something else for our purposes, given the complete lack of requirement for a reduction function.
SSIS vs Hadoop
I won’t go into detail on this, as Links has already written up the results over on thinknook.com, but running our Map function on a single SSIS instance performed significantly better in each test than our Hadoop cluster. The results we gathered seem to suggest that distributed is really only the correct approach when you areusing both the Map AND Reduce functionality and/or working with extremely large datasets. Indeed, the larger the dataset and the more data points involved, the more powerful and useful the reduce functionality becomes.
There is quite simply no straightforward alternative for performing this type of operation in traditional ETL platforms such as SSIS.
I’d like to find out what the comparison is like when performing this same test with Spark vs SSIS, just to see if the in-memory implementation provides the necessary performance boost, or if it’s still better to keep Map and MapReduce in two separate places.
Is Hadoop the right tool for the job?
Bottom line: It depends on the job.
If you’re not utilising both sides of the MapReduce coin though, even when processing millions of files, then the overhead of creating and managing jobs, is just not worth it. And if you are using both Map and Reduce functionality, it may just be worth considering some of the other solutions out there as an alternative to Hadoop MapReduce.