Hands-on with Hadoop and HDInsight
Hadoop. Everyone and their dog is talking about it. That and “Big Data”. There was an excellent post on Brent Ozar’s DBA Reactions Tumblr blog recently that encapsulated it perfectly, titled “When the executives ask if we’re Hadooping”. It’s a valid point though, Hadoop is mentioned in just about every article these days, along with the phrase “Big Data” (which I personally don’t like at all). The consensus, at least on the surface, seems to be that Hadoop will solve everyone’s problems, process anything, oh and bring world peace while it’s doing that. My sarcastic tone belies a genuine interest in playing about with it though. With so many people talking about Hadoop (in its many implementations), I was very keen to get an opportunity to try it for myself.
Fortunately, a project came along recently that seemed like it might benefit from a distributed processing approach. So naturally, being primarily a Microsoft Business Intelligence person, I figured the best place for me to get started was to jump onto Windows Azure and try out HDInsight, Microsoft’s own Hadoop implementation (in conjunction with Hortonworks).
Testing HDInsight
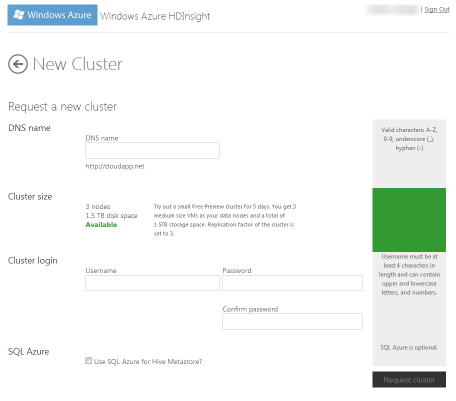
You can create your cluster in seconds
Getting started with HDInsight is simple. Incredibly simple. Just hit up https://www.hadooponazure.com/and sign-in to get started and request your cluster. The good news is, it’ll be live in minutes. the bad is that you can only get 3 nodes to begin with, which severely limits your processing capacity, except for only the simplest jobs.
This led me to actually discount HDInsight as a platform for this project soon after. Aside from the fact that at the time of writing, it’s still in preview stage (therefore no extra nodes, pricing information or scale-out options obviously available), on the default 3 nodes, we found that the performance was terribly slow, and the management of jobs and file system actually obscured somewhat by the web interface MS have added to try and simplify the experience. Even as a predominantly .NET/Windows person, I was much more comfortable configuring jobs and manipulating HDFS directly via the command line, rather than via the web interface (That could totally just be me though). If you use Remote Desktop to connect to your cluster, you can actually just launch the command line from there, and also browse HDFS using the HDFS web interface by connecting to the cluster’s head node.

You can manage all your jobs from the web interface
The preview nature of the platform was definitely a killer, at least for this project, as we were looking for something we could start with immediately, with the option to quickly boost capacity if necessary. One of the key selling points for using a distributed architecture has to be the ability to quickly and easily scale out capacity by adding more nodes to the cluster. Add to that the fact that we found performance to be very slow, and it was clearly not the best option for our purposes (To be completely fair though, my experiences with distributed processing solutions suggest they’re not the best choice for processing extremely large numbers of files, being more suited to handling smaller numbers of extremely large files).
Unfortunately, there’s not a huge amount of documentation available, and that which is available is not complete, so be prepared to roll up your sleeves and get your hands dirty.
Conclusion
I’m not for a second saying don’t try HDInsight though. As a project, it’s still in its infancy and perhaps not moving as quickly as some of the others out there. A Windows-based Hadoop implementation is still a very positive thing however, and while I didn’t really get on with the web UI, I’m sure others will find it fits their needs perfectly.
Pros:
- Easy to get started.
- Windows-based (pro for those familiar with Windows, at least).
- .NET code MapReduce functions.
- Awesome SDK.
- Pretty UI.
Cons:
- Slow, especially on the default 3 nodes.
- UI obscures Hadoop and HDFS functionality.
- Incomplete documentation.
- Still in preview stage.
I suggest that everyone gives it a go for themselves, as with most things in life (I was going to say in BI, but it’s equally applicable), one man’s trash is another man’s treasure, and depending on the requirements of each individual project, HDInsight may or may not be suitable. Would I recommend it at the moment, ahead of a Linux-hosted Hadoop implementation? No, I have to say I probably wouldn’t, but it’s good to see Hadoop hit Windows regardless, and there is definite promise in HDInsight.
It just needs to haul itself up off its hands and knees and take those first couple of tentative steps.